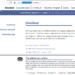
2023 年 6 月 5 日 topadmin 【PHP編輯器】Blumentals Rapid PHP Editor 2020 結合了功能齊全的PHP IDE的功能和記事本的速度 Rapid PHP編輯器是用於Windows的更快...
2023 年 6 月 5 日 topadmin 【建立.編輯MySQL資料庫】EMS SQL Manager for MySQL v5.7.2 MySQL資料庫管理和開發的高效能工具 EMS SQL Manager for MySQL...