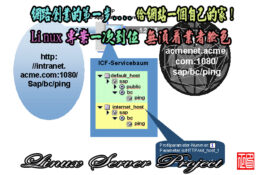
Linux主機架設.維護專案
您要運用網路開展事業或在網路上創業賺錢的第一步就是:需要一台Linux主機伺服器,替你24小時全年無修提供服務!(總教頭_提供Linux主機伺服器架設及維護!)
Latest News
Linux主機指令大全